物联网设备上云首选
ThingsCloud 服务于数万家不同规模的企业,帮助他们在极短的时间内搭建个性化的物联网平台和应用,推动数字化和智能化升级。
轻松接入设备
通过标准协议及自定义协议,任何硬件设备都可直连或通过网关接入 ThingsCloud。
上手简单
容易上手,不需要繁琐配置,开箱即用的云端服务。
零代码应用开发
无需编写代码,一键生成 SaaS、App、小程序、H5 等,快速搭建物联网智能场景和行业应用。
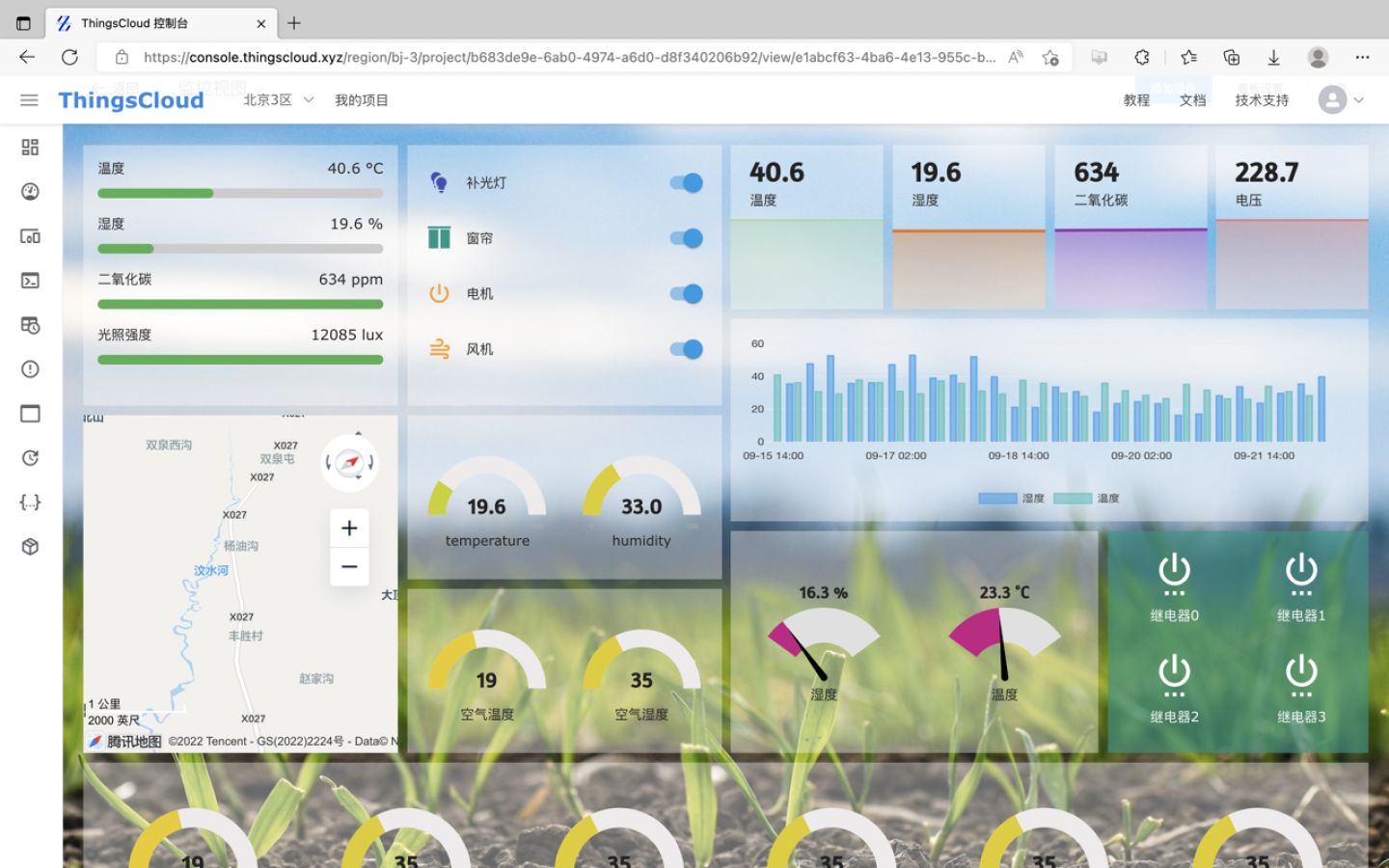
可视化看板
提供丰富的看板组件,任何人都可以制作酷炫的物联网可视化看板。
应用端 API
通过应用端 API,集成设备资产及数据到企业信息化系统。
消息规则
强大的云端消息处理组件,支持协议处理和数据流转,以及自定义云函数。
任务
支持设备批量任务,以及多种定时策略。
告警规则
内置设备告警规则,支持多种告警条件灵活配置。
通知组
支持 Email、短信、公众号、企业微信、钉钉、飞书等告警通知。
OTA 固件升级
提供设备固件版本管理,以及 OTA 远程升级能力。
消息调试
通信消息实时查看,易于维护和排查故障。
自定义数据流
支持二进制、JSON、ASCII 等自定义数据流格式。
Modbus 云网关
通过云网关,Modbus 多路传感器可映射到多台设备。
TCP 透传
不仅支持 MQTT/HTTP ,还支持 TCP 设备接入。
时序数据分析
内置设备时序数据分析功能,生成统计图表。
产品模板库
面向设备厂商,可共享产品设备类型。